Sollte ein persönliches Interview nicht möglich sein, achtet auch beim Telefoninterview auf die bestmögliche Audioqualität.
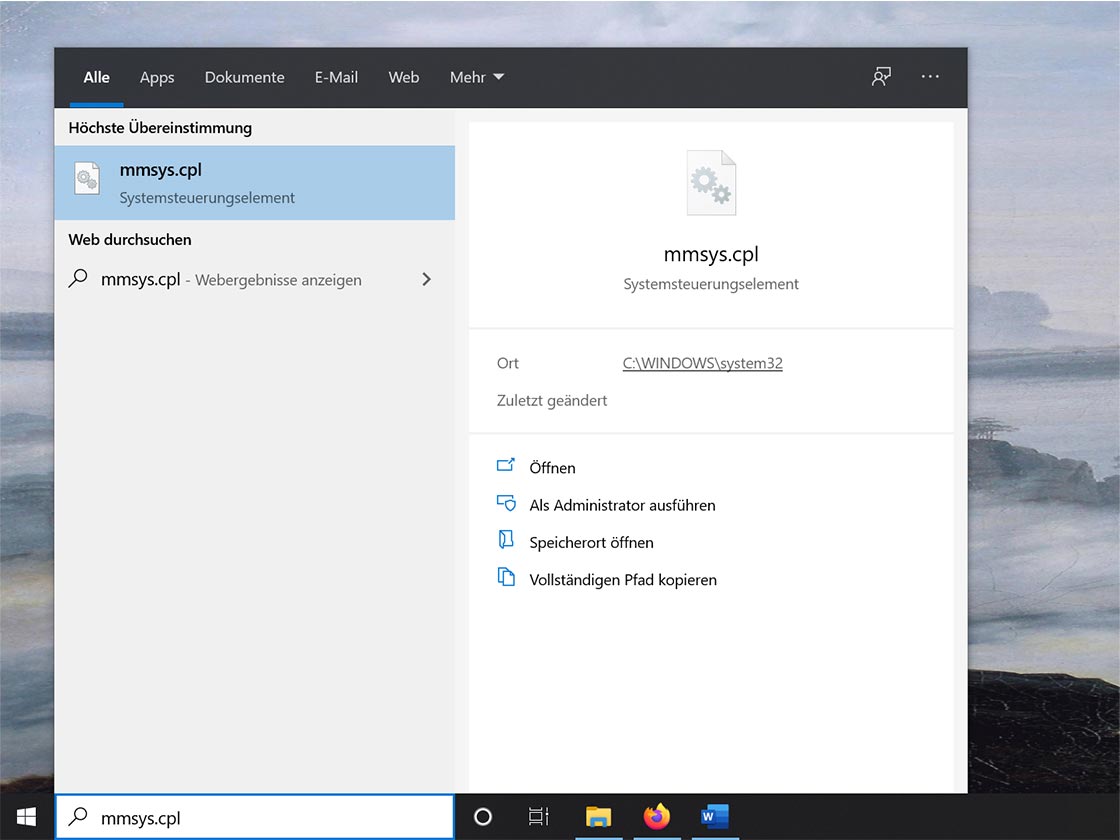
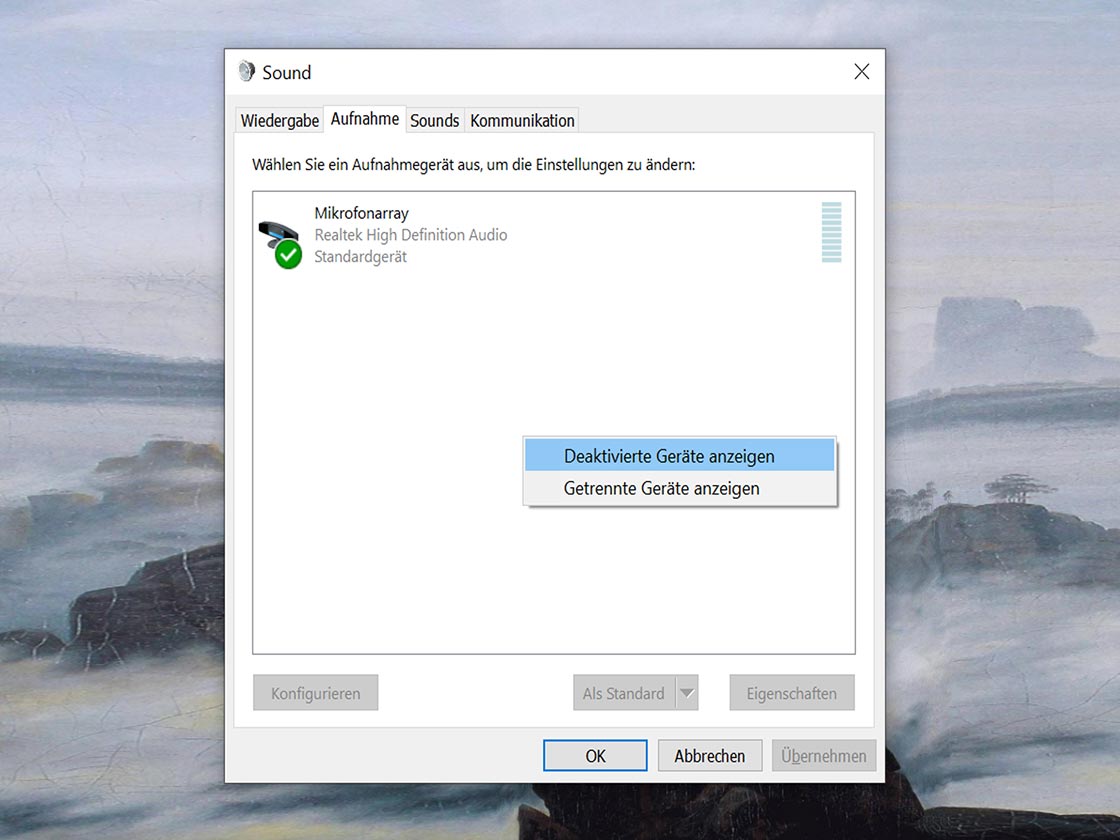
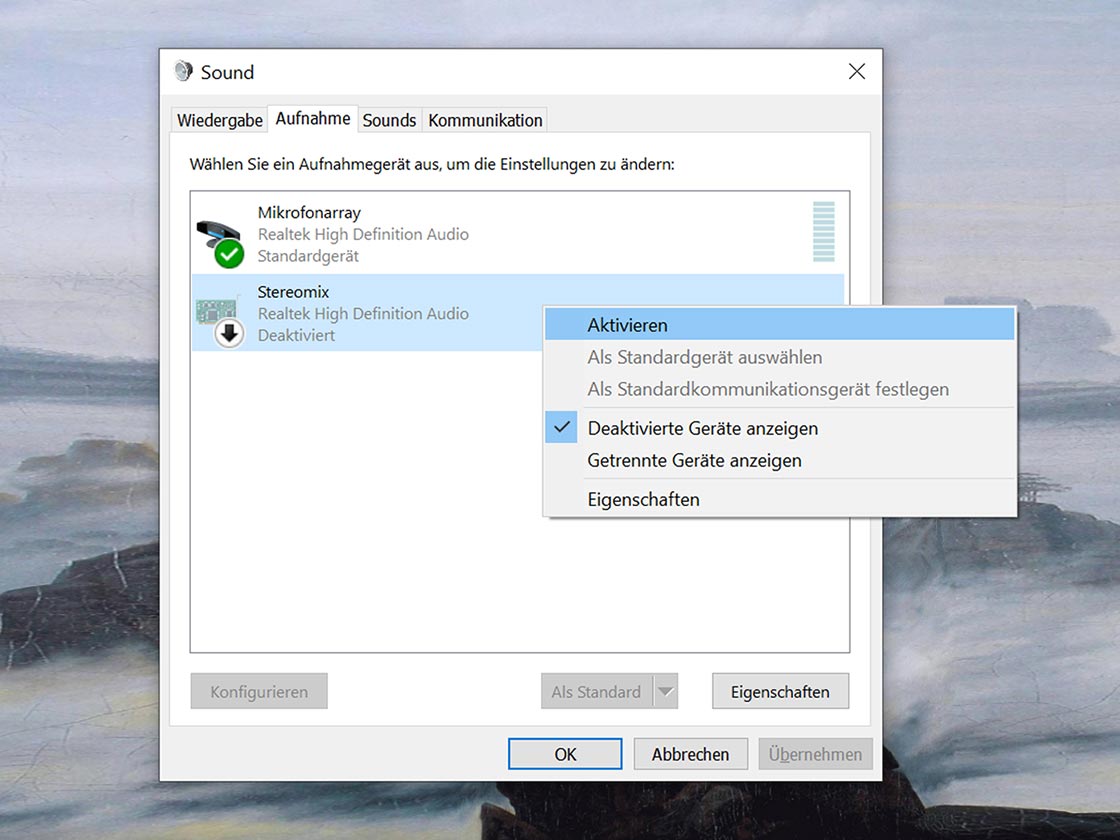
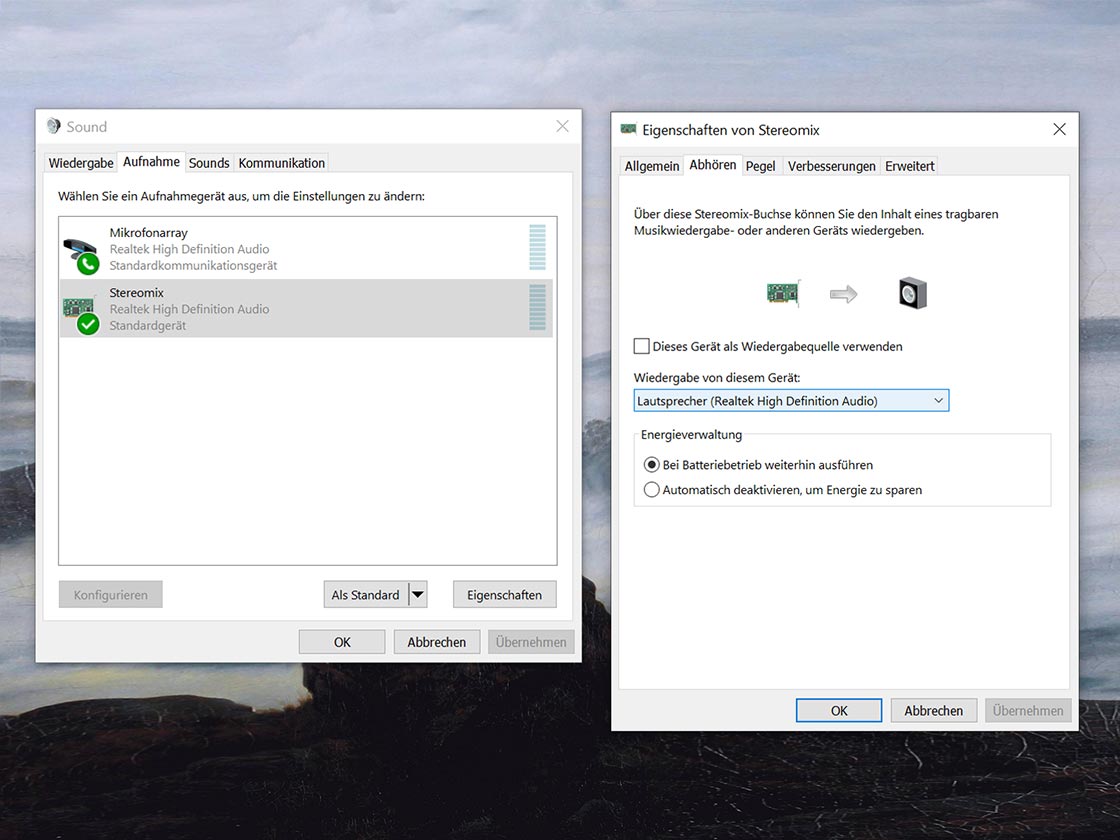
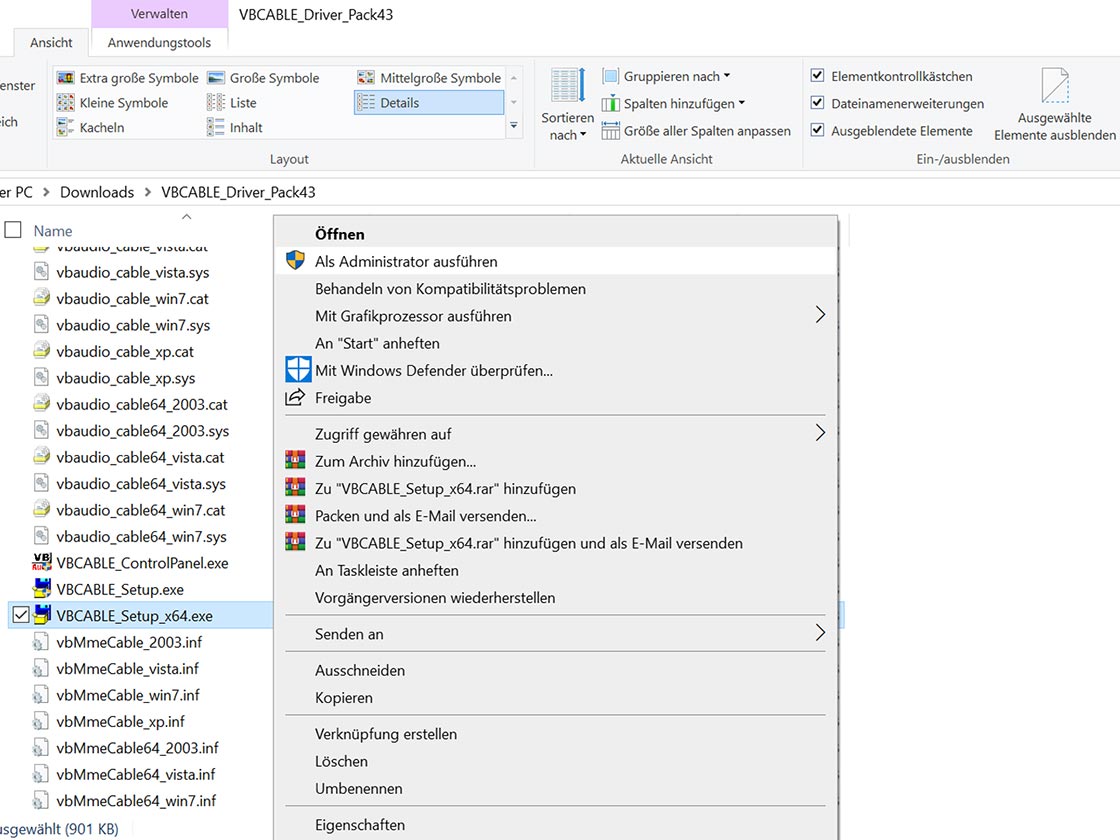
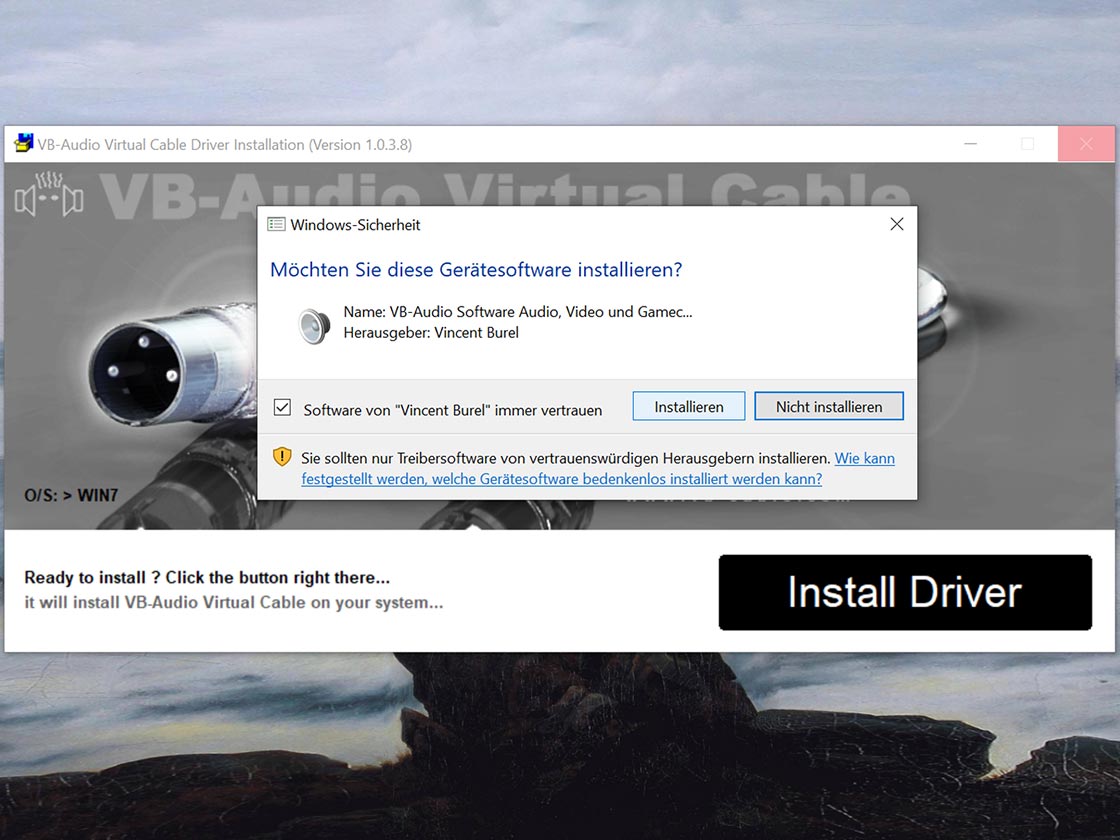
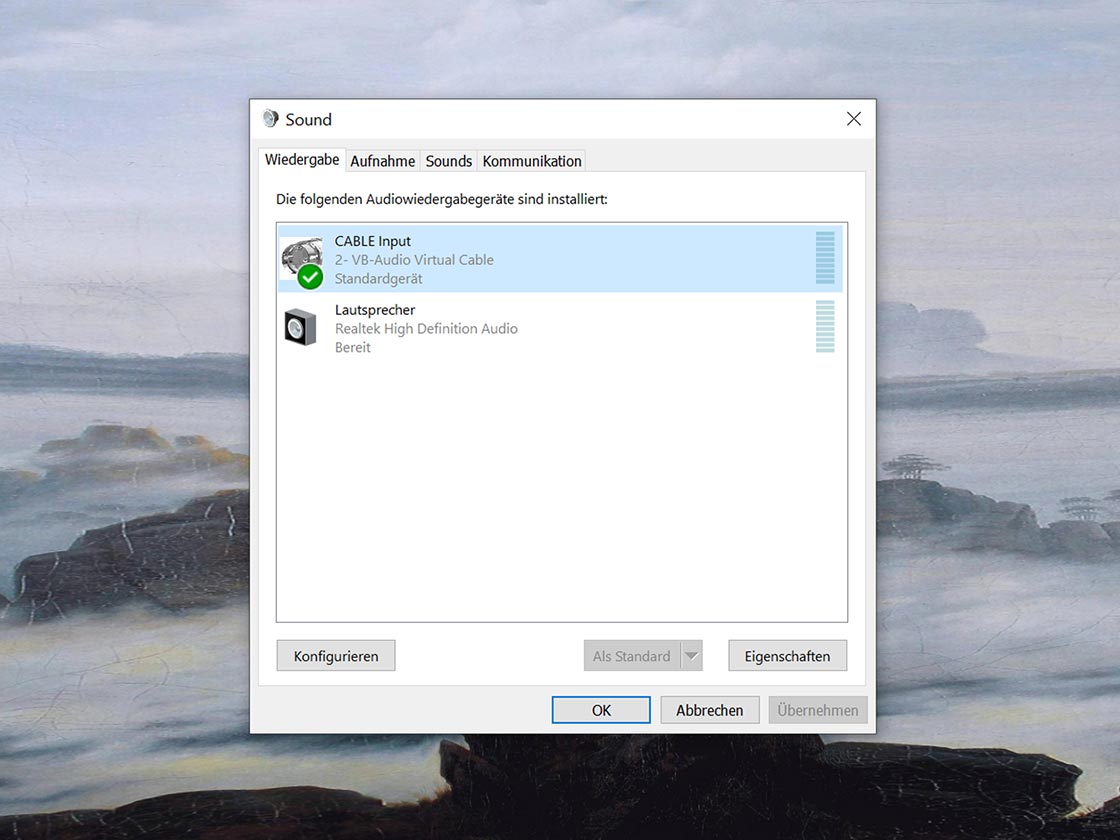
Bei der Aufnahme eines Interviews über ein Festnetztelefon sollte ein Telefon-Aufnahmeadapter genutzt werden. Die Aufnahme kann dann beispielsweise über einen PC erfolgen.



Noch kein Kommentar, Füge deine Stimme unten hinzu!